‘≠òÀÓ}:壑L | œ»¬ïΩÔ˝CTO«ÿ˝à£∫”–œÞµƒÀ„∑®≈cüoœÞµƒ–¬“‚
°∏‘⁄ΩÔ˝ÓI”Ú◊ˆ∫√£¨≤ª «’f“™∞—ƒ≥“ªÇÄÃÿ∂®À„∑®◊ˆµΩòO÷¬£¨∂¯ «»Á∫Œ∞—œýå¶≥… ϵƒºº–g≈cΩÔ˝µƒΩY∫œ◊ˆ∫√°£°π
°∂þBæÄ°∑Îs÷æ‘⁄øÇΩY 2017 ƒÍ»Àπ§÷«ƒÐÓI”ÚåW–g—–æø¨FÝÓïr£¨Ã·µΩ¡À“ªÇÄì˙ën£¨º¥Æî«∞¥Û∂ýîµ»Àπ§÷«ƒÐºº–gµƒ∞l’π∂ºòO∂»“¿ŸáòO…Ÿîµ∫À–ƒÑì–¬À„∑®µƒ÷ß≥÷£¨ìQ扑í’f£¨À„∑®þ@ ¬£¨“≤ï˛”–°∏…Æ∂ý÷ý…Ÿ°πµƒÜñÓ}°£µƒ¥_£¨…ÒΩõæWΩj≤ª «æÌ∑e…ÒΩõæWΩjæÕ «—≠≠h…ÒΩõæWΩj£¨Ãé¿Ìµƒå¶œÛøÇÔ≤ªþ^’Z“Ù°¢àDœÒ°¢Œƒ±æ£¨∂¯Ìò¿Ì≥…’¬µƒë™”√Àº¬∑“≤æÕ÷«ƒÐ“Ùœ‰°¢»Àƒò◊RÑeþ@√¥é◊ÇÄ°£“Ú¥À…–Œ¥ÕÍ»´≥…“郣µƒú\û© –àˆ¿Ô“—ΩõîDþM¡Àô∂ýµƒ÷ÿ∞ııèÙ~–Õþx ÷£¨À{∫£∫√œÒ÷ª «“ªÇĪ√”X£¨∫£ÀÆ“ª÷± «…Óºt…´°£
Œ“éß÷¯å¶þ@“ª”^¸cµƒ’JÕ¨Ω””|µΩ¡À«ÿ˝à£¨œ»¬ïΩÔ˝ CTO£¨»ª∫Û∏– ÐµΩ¡Àþ@º“√˚◊÷¿Ô√Ê…ı÷¡õ]≥ˆ¨F°∏÷«ƒÐ°πªÚ’þ°∏ø∆ºº°π◊÷ò”µƒπ´ÀæéßÅ̵ƒÛ@œ≤£∫π§≥ÃéüÇÉø∞∑Q°∏πÌ∏´…Òπ§°πµÿ∞—Œ“ÇÉ»Á“’‰µƒÀ„∑®◊É≥ˆ¡Àª®ò”£¨»ª∫ÛΩo≥ˆ¡À“ªÇĺ»≥‰∑÷¿˚”√¡À¨FÎA∂Œµƒºº–g∞l’πÀÆ∆Ω£¨Õ¨ïræþ”–≤ªÂeµƒø…îU’π–‘µƒ∞l’π¬∑èΩ°£
ìQ扑í’f£¨À˚ÇɵƒÀ„∑®º»ƒÐâÚÌò¿˚¬‰µÿ£¨‘⁄Æîœ¬Ω‚õQåç¥Úå絃–Ë«Û£¨ ÷Œ’»’æ˘«ß»f¥Œµƒ∑˛Ñ’’à«Û£¨Õ¨ïr“ªµ©ƒ«–©ÇÄ AI À„∑®ΩÒÃÏÆãþ^µƒÔû√˜ÃϒʵƒƒÐ≥‰á¡À£¨“≤ƒÐ”√Õ¨ò”µƒÀº¬∑‘ŸÃ·∏þ“ªÇÄ≈_ÎAÃÙë∏¸èÕÎsµƒÜñÓ}°£
þ@æÕ «°∏À„∑®µƒ–¬“‚°πµƒ÷ÿ“™–‘°£
µ⁄“ªÇÄ–¬“‚ÅÌ◊‘嶒Z“Ù◊RÑeµƒƒÊœÚÀºæS°£
Œ“ÇÉ”°œÛ¿Ôµƒ’Z“Ù◊RÑe»ŒÑ’£¨ «¥Ê‘⁄°∏”√ëÙæÕ «…œµ€°πµƒú Ñtµƒ£∫”√ëÙ’f‘íï˛éß÷¯Ãσœµÿ±±µƒø⁄“Ù£¨À˘“‘È_∞l’Z“Ùðî»Î∑®µƒàFÍÝ“™ ’ºØ¥Û¡ø∑Ω—‘îµì˛◊僣–Õ°∏“ä∂ý◊RèV°π£ª”√ëÙøÇ «Îx÷¯˚úøÀÔL∫ÐþhæÕÈ_ º∞lÃñ ©¡Ó£¨À˘“‘È_∞l÷«ƒÐ“Ùœ‰µƒàFÍÝ“™≤º÷√˚úøÀÔLÍá¡–ÅÌΩ‚õQ°∏ÎuŒ≤æ∆ï˛ÜñÓ}°π°£æÕÀ„‘⁄òÀú îµì˛ºØ…œ£¨À„∑®‘ÁæÕ◊∑…œ»ª∫ÛƒÎâ∫¡À»ÀÓ꣨Œ“ÇÉ“ªò”ï˛“‘°∏≤ªï˛◊ÉÕ®°π£¨°∏≤ªΩ‚õQåçÎHÜñÓ}°πûÈ¿Ì”…µ≠ªØÀ¸Çɵƒ≥…æÕ°£
ƒ«√¥£¨”–õ]”–ø…ƒÐìQ“ª∑NÀº¬∑£¨’““ªÇÄ≤ª «°∏À„∑®þwæÕ…∆◊ɵƒ»ÀÓê°π£¨∂¯ «°∏»ÀÓꃣ∑¬òÀú µƒÀ„∑®°πµƒ«Èæ∞£¨∞—≤ªï˛≥ˆÂe°¢≤ª∏„Ãÿ ‚ªØµƒÀ„∑®∑≈‘⁄’˝¥_¥∞∏µƒŒª÷√£¨≤ª÷™∆£æεÿΩo»ÀÓê°∏’“≤Á°π£ø
œ»¬ï∏Ê‘VŒ“ÇÉ£∫”–£¨þ@ÇÄ¥∞∏Ω–◊ˆø⁄’Zúy‘u°£
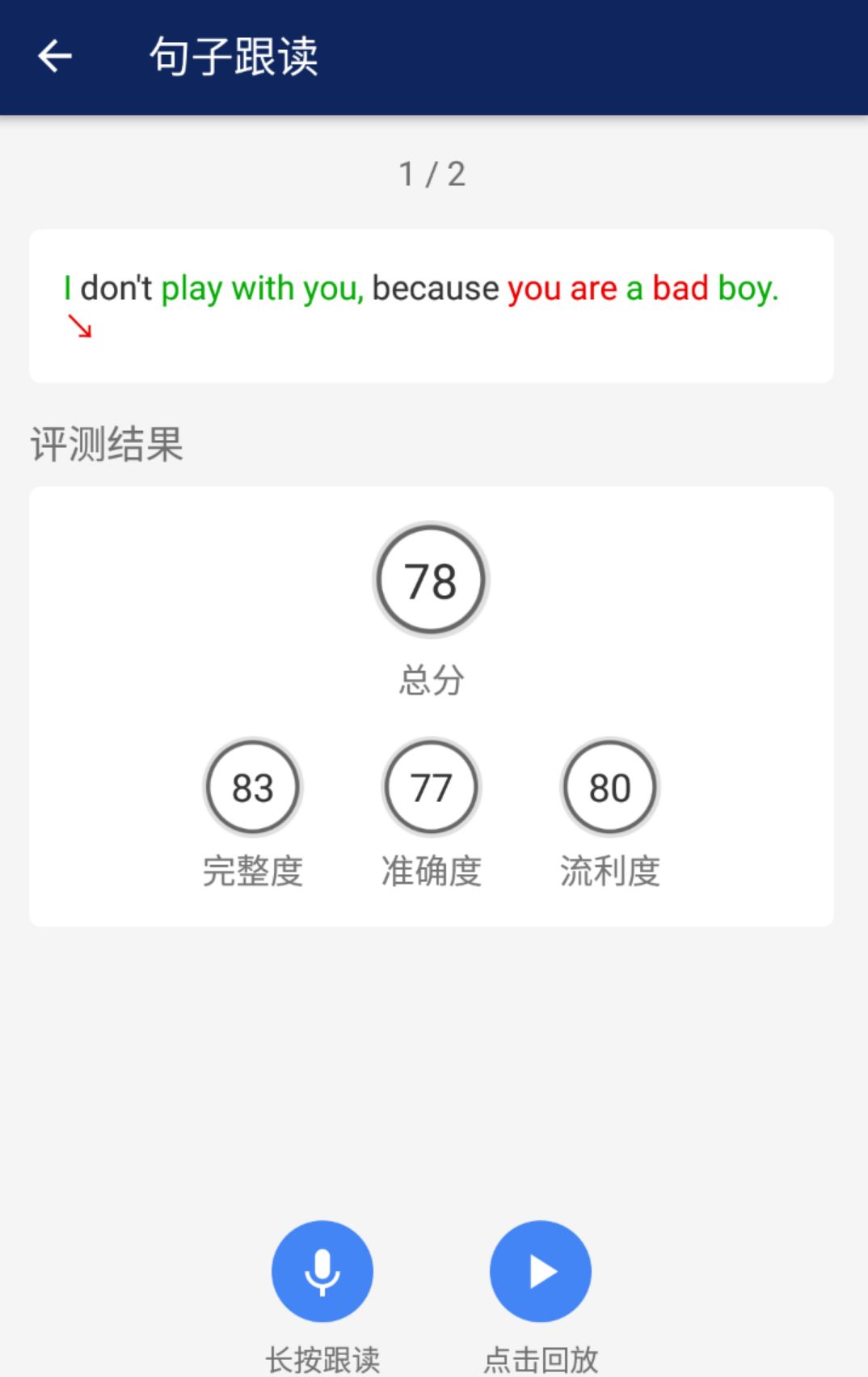
Œ“éß÷¯—≈Àºø⁄’Z 8 ∑÷µƒ◊‘–≈‘á”√¡À°∏æ‰◊”∏˙◊x°ππ¶ƒÐ£¨±ªÀ„∑®ðpÀ…◊•≥ˆ¡À»˝Ãé–ƒ∑˛ø⁄∑˛µƒÂe’`£∫
È_Ó^µƒ…˝Ωµ’{Âe’`£¨ÅÌ◊‘Œ“°∏‘~ÖR¡ø≤ª◊„«ÈæwÅÌúê°πµƒ¡ïëT–‘ø‰èà’Z’{°£ ÷–ÈgµƒòÀºtÅÌ◊‘ÕÓÙþB◊x£¨æÕœÒåëëT¡À––ﯵƒ»À±ªèä∆»åë’˝ø¨øÇ «Õµ¬©πPÑù°£ ÃÿÑe‘˙–ƒµƒ «ΩYŒ≤ƒ«ÇÄ°∏bad°π£∫‘≠ÅÌŒ“∞lÈ_‘™“Ù≤ªèà◊Ïþ@ÇÄÆîƒÍ—≈Àº÷˜øºπŸ÷∏≥ˆþ^µƒâƒ¡ïëT£¨÷¡ΩÒ“≤õ]∏ƒµÙ£°
«µƒ£¨ƒ„ø…“‘≈˙‘u AI ≤ªƒÐ°∏Ï`ªÓë™◊É°π£¨Ös–Ë“™≥–’JÀ¸”¿þh°∏±M¬ö±Mÿü°π£¨À¸ªÚ‘S◊ˆ∆–°π§°∏Õ»Á÷«’œ°π£¨µ´◊É…ÌûÈ¿œéüÖs°∏”–ƒ£”–ò”°π°£
ø⁄’Zúy‘u±≥∫Ûµƒ…ÒΩõæWΩj∫ÕôC∆˜¬Ýåë°¢÷«ƒÐ“Ùœ‰üoÆ꣨∂º «ª˘”⁄ lstm RNN µƒ’Z“Ù◊RÑeƒ£–Õ°£‘uúyþ^≥ÿԣ¨œµΩyï˛∞—¬ï“Ù«–∏ÓµΩ“ÙÀÿ£®phoneme£©ºâÑe£¨ ◊œ»≈–îý°∏”–õ]”–°π£¨º¥’Z“Ù∆¨∂Œ÷– «∑Ò∫¨”–À˘”–“ÙÀÿ£¨Ωo≥ˆÕÍ’˚∂»µ√∑÷£ª»ª∫Û≈–îý°∏å¶≤ªå¶°π£¨÷ÇÄå¶∞l“Ù°¢÷ÿ“Ù£®stress£©Œª÷√“‘º∞’Z“Ù’Z’{µƒ’˝¥_–‘þM––Ðõ∑÷Ó꣨Ωo≥ˆú ¥_∂»¥Ú∑÷£ª◊Ó∫Û‘⁄æ‰◊”å”√Ê£¨å¶’’ÜŒ‘~ïrÈLµƒ∑÷≤º–≈œ¢°¢‘~÷ÆÈgµƒÕ£ÓD°¢øÇÛwµƒ’ZÀŸ£¨Ωo≥ˆ¡˜¿˚∂»µ√∑÷°£Ωõþ^þ@“ª’˚ÇÄ¡˜≥㨓ڥÀ£¨þ@ÇÄ“ÙÀÿºâÑeµƒƒ£–ÕƒÐâÚΩoƒ„‘îºöµΩ“ÙÀÿÀÆ∆Ωµƒ–Þ∏ƒ“‚“䣨◊÷’Âæ‰◊√µÿ∫Õƒ„Õ∆«√∞l“Ù°£
þ@¿Ô’π 浃ÉHÉH «“ªÇÄ”–¥_∂®–‘¥∞∏µƒøÕ”^Ó}£¨‘ŸÎy“ª–©µƒ∑«¥_∂®–‘¥∞∏∞ÎÈ_∑≈–‘Ó}ƒø“≤ø…“‘ÓêÀ∆Ãé¿Ì°£œ»¬ïµƒòIÑ’·òå¶ K12£®Kindergarten to Grade 12£¨åW˝g«∞µΩ∏þ÷–£©’πÈ_£¨∆‰÷–∑«≥£µ‰–ÕµƒÜñÓ} «÷–øºµƒø⁄Ó^◊˜Œƒ£∫
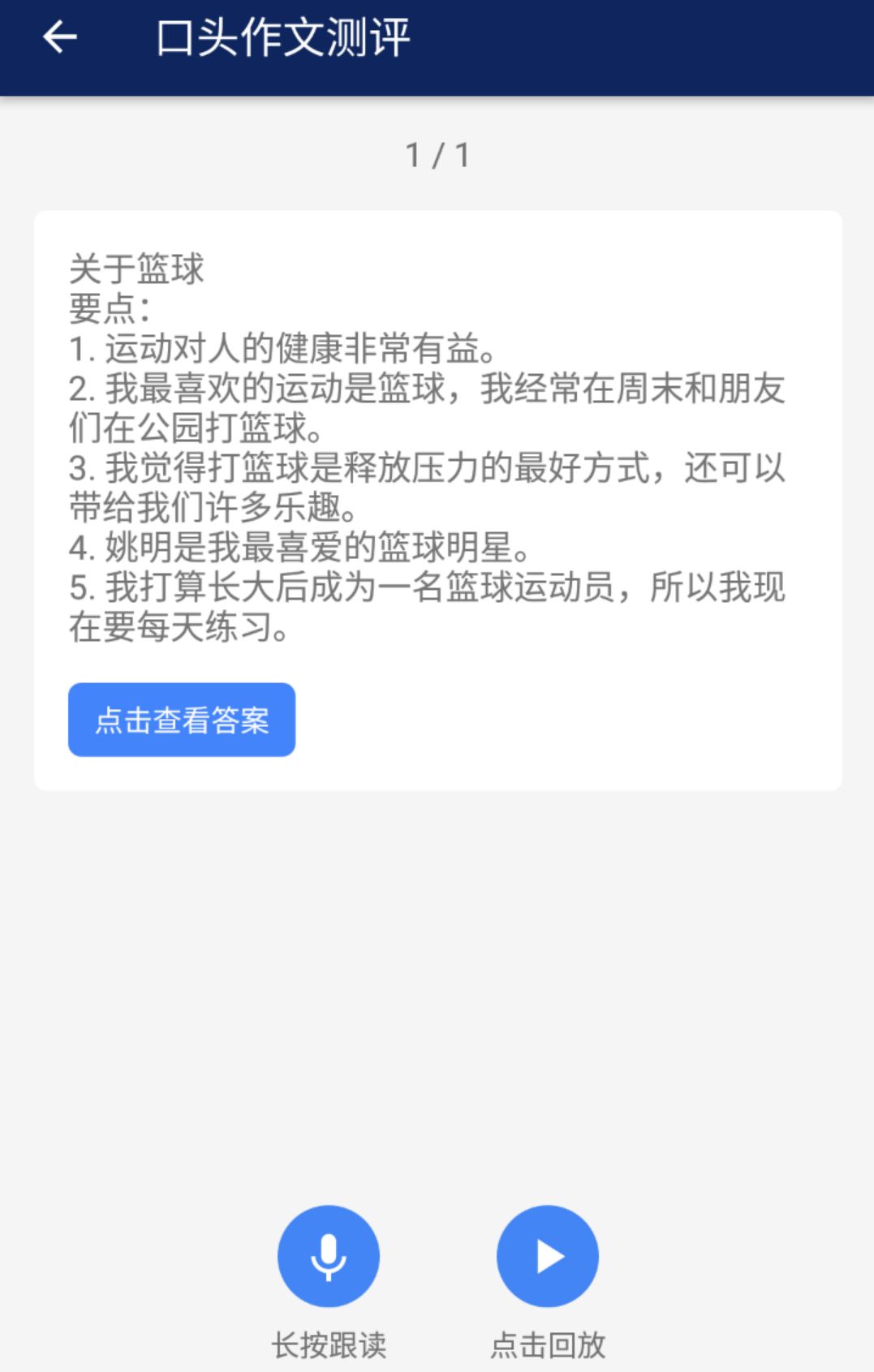
œý±»”⁄∏˙◊x£¨ø⁄Ó^◊˜ŒƒþÄ“™‘⁄’Z“Ù◊RÑe∫Ûº”…œ◊‘»ª’Z—‘Ãé¿Ì≥Öڣ¨≈–îýøº…˙ «∑Ò∏≤…wÓ}ƒøÀ˘“™«Ûµƒ“™¸c£∫≥˝¡À‘⁄øº…˙µƒ¥∞∏¿Ô姒“òÀú ¥∞∏ÍPÊI‘~÷ÆÕ‚£¨“≤“™”√‘~«∂»Î£®word embedding£©å§’“Ω¸¡x‘~∫Õ‘~ΩM£¨±»»ÁòÀú ¥∞∏ «°∏Basketball is good for health.°π£¨øº…˙”√¡À°∏Playing basketball is a healthy habit.°π“≤“ªò”뙑ìµ√∑÷°£
µ⁄∂˛ÇÄ–¬“‚ÅÌ◊‘å¶ôC∆˜∑≠◊gµƒ¡ÌÓê¿˚”√°£
∆‰åç°∏∆Ω––’Z¡œ°π≤¢≤ª“ª∂®æ÷œÞ”⁄É…∑N’Z—‘£¨÷ª“™ «”–å¶ë™ÍPœµµƒ’Zæ‰å¶£¨∂ºø…“‘”√°∏æé¥a∆˜-Ω‚¥a∆˜°πµƒôC∆˜∑≠◊gÀº¬∑ÅÌΩ‚°£‘⁄åWΩÁ£¨þ@ÇÄÀº¬∑±ªîU’πµΩ¡ÀÜñ¥œµΩyµƒ‘O”㣨∂¯œ»¬ïþxìÒ¡À¡Ì“ªÇÄ∆Ê√Óµƒ’Z—‘嶣∫°∏”–’Z∑®Âe’`µƒæ‰◊”°π∫Õ°∏∏ƒµÙ¡À’Z∑®Âe’`µƒ’˝¥_æ‰◊”°π°£”⁄ «£¨◊˜Œƒ≈˙∏ƒæÕþ@ò”◊É≥…¡À“ªÇÄ∫ܪØ∞ʵƒôC∆˜∑≠◊gÜñÓ}°£
÷ÆÀ˘“‘’f «∫ܪØ∞Ê£¨ «“ÚûÈ◊˜Œƒ≈˙∏ƒ÷–Õ®≥£…ʺ∞µƒ∏ƒÑ”∑∂á˙∂º±»ð^–°£¨õ]”–ôC∆˜∑≠◊g÷–”…”⁄≤ªÕ¨’Z—‘µƒ’Z∑®ΩYòã≤ÓÆê∂¯Æa…˙µƒÈL扖£ú ÜñÓ}°£À˘“‘£¨≈˙∏ƒ≤ª–Ë“™◊¢“‚¡¶ôC÷∆°¢…ı÷¡≤ª–Ë“™∑«≥£œ˚∫ƒ”ãÀ„ŸY‘¥µƒ…Ó∂»…ÒΩõæWΩj£¨ƒƒ≈¬ «Ç˜ΩyµƒΩy”ãôC∆˜∑≠◊g£®SMT£©£¨“≤ƒÐ»°µ√≤ªÂeµƒ–ßπ˚°£